
HashMap
大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。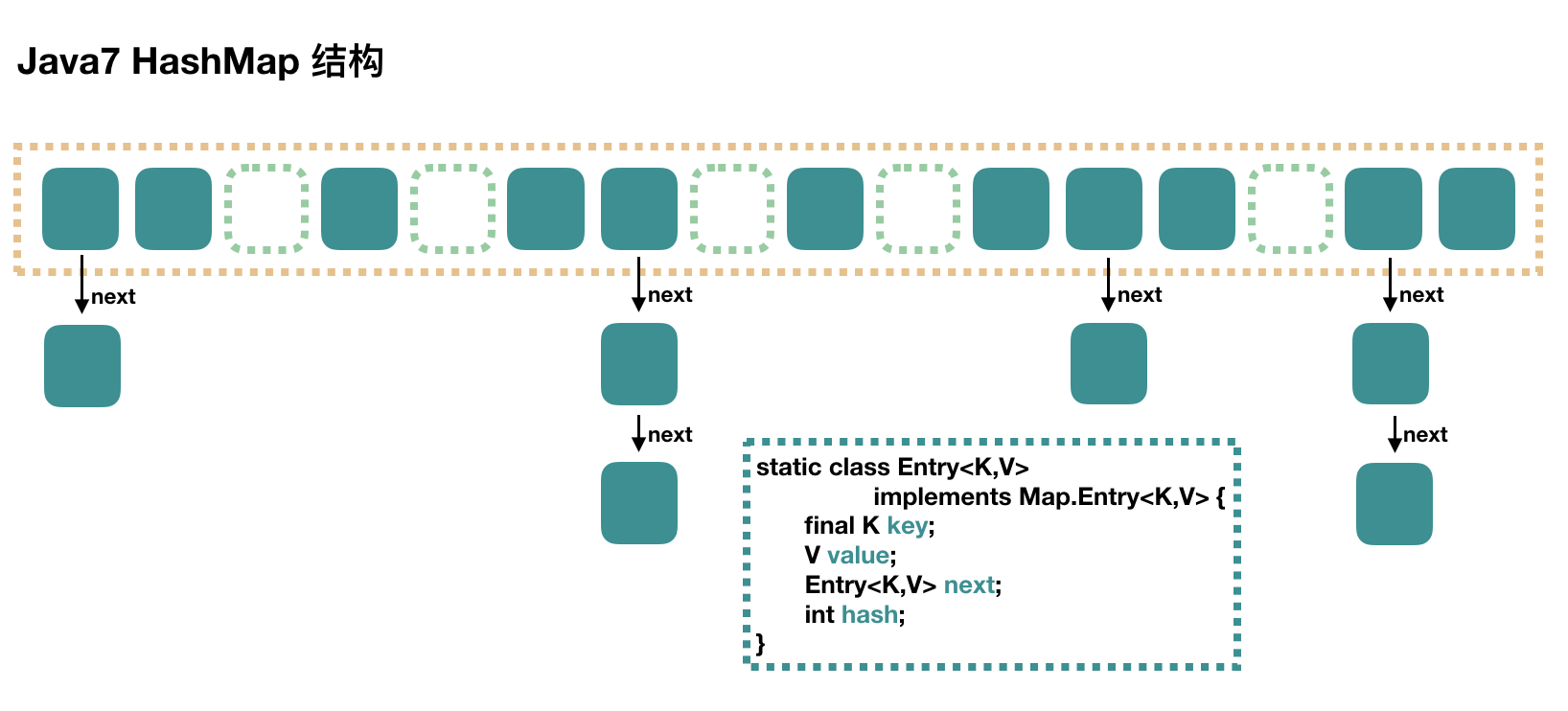
上图中,每个绿色的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next。
Java8 中将单项链表改为了红黑树。关于红黑树是什么,数据结构-树中有简单介绍。
几个重要属性:
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
loadFactor:负载因子,默认为 0.75。
threshold:扩容的阈值,等于 capacity * loadFactor
为什么hashmap数组容量要保持为2的n次方?
一般我们利用hash码, 计算出在一个数组的索引, 常用方式是”h % length”, 也就是求余的方式。
可是这种方式效率不高, “当容量一定是2^n时,h & (length - 1) == h % length” 。按位运算特别快 。
对于length = 16, 对应二进制”1 0000”, length-1=”0 1111”
假设此时h = 17 .
(1) 使用”h % length”, 也就是”17 % 16”, 结果是1
(2) 使用”h & (length - 1)”, 也就是 “1 0001 & 0 1111”, 结果也是1
我们会发现, 因为”0 1111”低位都是”1”, 进行”&”操作, 就能成功保留”1 0001”对应的低位, 将高位的都丢弃, 低位是多少, 最后结果就是多少 。
刚好低位的范围是”0~15”, 刚好是长度为length=16的所有索引 。
put 过程分析
1)数组初始化
在第一个元素插入 HashMap 的时候做一次数组的初始化,就是先确定初始的数组大小,并计算数组扩容的阈值。这里有一个方法将数组大小保持为 2 的 n 次方。
2)计算具体数组位置
原理:使用 key 的 hash 值对数组长度进行取模就可以了。
实现:取 hash 值的低 n 位。如在数组长度为 32 的时候,其实取的就是 key 的 hash 值的低 5 位,作为它在数组中的下标位置。
3)添加节点到链表中
找到数组下标后,会先进行 key 判重,如果没有重复,就准备将新值放入到链表的表头。
4)数组扩容
在插入新值的时候,如果当前的 size 已经达到了阈值,并且要插入的数组位置上已经有元素,那么就会触发扩容,扩容后,数组大小为原来的 2 倍。
get 过程分析
1)根据 key 计算 hash 值。
2)找到相应的数组下标:hash & (length – 1)。
3)遍历该数组位置处的链表,直到找到相等(==或equals)的 key。
ConcurrentHashMap
ConcurrentHashMap 和 HashMap 思路是差不多的,但是因为它支持并发操作,所以要复杂一些。
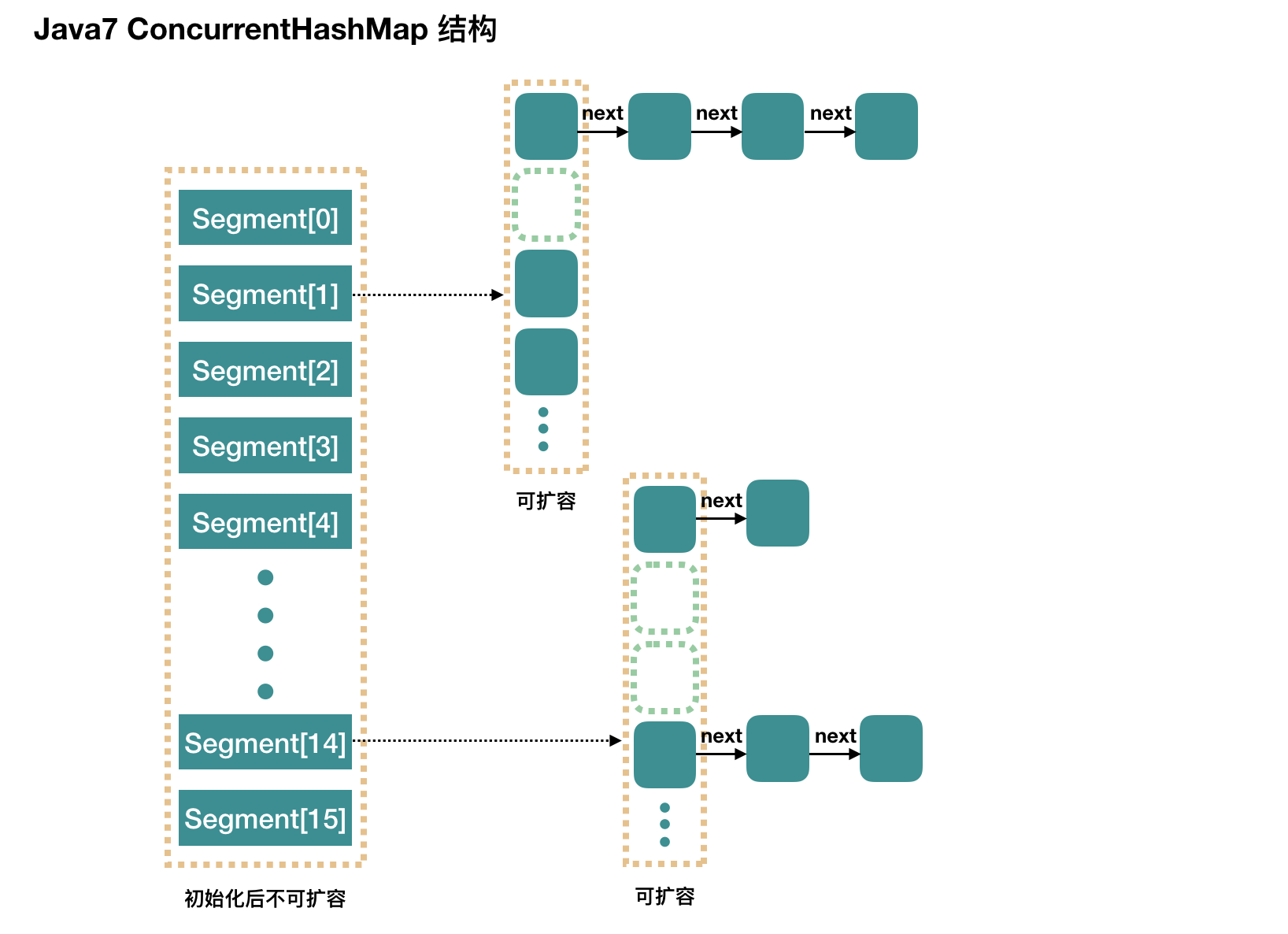
ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
几个重要属性
concurrencyLevel:并行级别、并发数、Segment 数。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 Segment。
loadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的。
例:我们就当是用 new ConcurrentHashMap() 无参构造函数进行初始化的,那么初始化完成后:
Segment 数组长度为 16,不可以扩容。
Segment[i] 的默认大小为 2,负载因子是 0.75,得出初始阈值为 1.5,也就是以后插入第一个元素不会触发扩容,插入第二个会进行第一次扩容
这里初始化了 segment[0],其他位置还是 null。
当前 segmentShift 的值为 32 – 4 = 28,segmentMask 为 16 – 1 = 15,姑且把它们简单翻译为移位数和掩码,这两个值马上就会用到
初始化槽: ensureSegment
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽来说,在插入第一个值的时候进行初始化。之所以要先初始化segment[0],是因为初始化其他槽的时候会使用当前 segment[0] 处的数组长度和负载因子。为什么要用“当前”,因为 segment[0] 可能早就扩容过了。
put 过程分析
1) 根据 hash 值很快就能找到相应的 Segment,之后就是 Segment 内部的 put 操作了。
hash 是 32 位,无符号右移 segmentShift(28) 位,剩下高 4 位,然后和 segmentMask(15) 做一次与操作,也就是说 j 是 hash 值的高 4 位,也就是槽的数组下标1
int j = (hash >>> segmentShift) & segmentMask;
2)Segment 内部是由 数组+链表 组成的,put方法基本就是一个上锁了的hashmap put
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽来说,在插入第一个值的时候进行初始化。这里需要考虑并发,因为很可能会有多个线程同时进来初始化同一个槽 segment[k],不过只要有一个成功了就可以。
获取写入锁: scanAndLockForPut
在往某个 segment 中 put 的时候,首先会调用 node = tryLock() ? null : scanAndLockForPut(key, hash, value),也就是说先进行一次 tryLock() 快速获取该 segment 的独占锁,如果失败,那么进入到 scanAndLockForPut 这个方法来获取锁。
扩容: rehash
重复一下,segment 数组不能扩容,扩容是 segment 数组某个位置内部的数组 HashEntry[] 进行扩容,扩容后,容量为原来的 2 倍。
get 过程分析
1)计算 hash 值,找到 segment 数组中的具体位置,或我们前面用的“槽”
2)槽中也是一个数组,根据 hash 找到数组中具体的位置
3)到这里是链表了,顺着链表进行查找即可
注:java8中ConcurrentHashMap链表由单链表改成了红黑树。
HashSet
HashSet
其基于HashMap实现,内部有个字段为hashMap。例如以下所看到的:
基于map实现。键为元素,值为固定的PRESENT
private transient HashMap<E,Object> map;