
此篇文章仅从理论上介绍Redis的基本数据类型,有关各类型的具体操作,可见Redis常用命令总结
更多Redis入门系列文章,参见Redis入门-大纲
RedisObject
Redis内部使用一个redisObject对象来表示所有的key,value。
type代表一个value对象具体是何种数据类型,有5种基本数据类型,分别是:String、List、Set、Hash、SortedSet(ZSet)。
encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:”123” “456”这样的字符串。
redisObject中的encoding
1 | \#define OBJ_ENCODING_RAW 0 /* Raw representation */ |
type与encoding对照表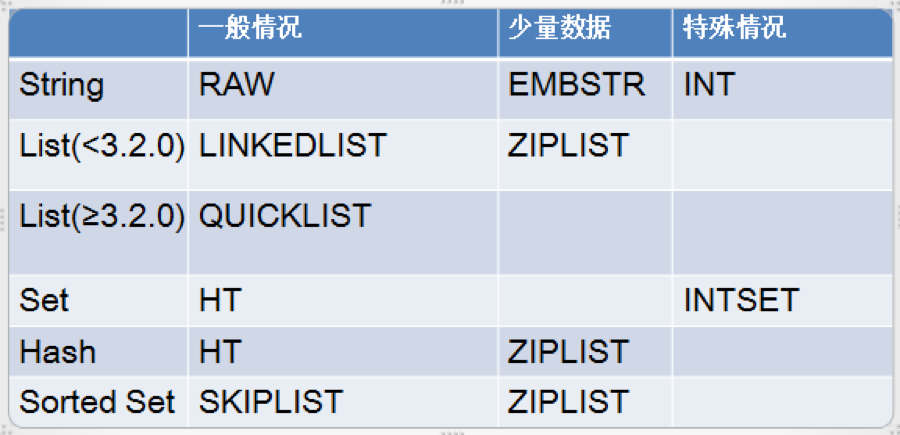
String
value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。也可以以json字符串形式存储对象。
实现方式:字符串对象的编码可以是int、raw或者embstr。如果一个字符串的内容可以转换为long,那么该字符串就会被转换成为long类型,对象的ptr就会指向该long,并且对象类型也用int类型表示。普通的字符串有两种,embstr和raw。embstr应该是Redis 3.0新增的数据结构,在2.8中是没有的。如果字符串对象的长度小于39字节,就用embstr对象。否则用传统的raw对象。
embstr的创建只需分配一次内存,而raw为两次(一次为sds分配对象,另一次为object分配对象,embstr省去了第一次, SDS是redis自定义的一种简单动态字符串)。相对地,释放内存的次数也由两次变为一次。embstr的objet和sds放在一起,更好地利用缓存带来的优势。
需要注意的是,redis并未提供任何修改embstr的方式,即embstr是只读的形式。对embstr的修改实际上是先转换为raw再进行修改。
Hash
这里value存放的是HashMap<String,String>,比较方便的就是操作其中的某个字段。例如在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
实现方式: Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为ziplist,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
List
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。 LIST还可以很好的完成排队,先进先出的原则。
实现方式:Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。在Redis 3.2版本之前,一般的链表使用LINKDEDLIST编码。在Redis 3.2版本开始,所有的链表都是用QUICKLIST编码。两者都是使用基本的双端链表数据结构,区别是QUICKLIST每个节点的值都是使用ZIPLIST进行存储的。
Set
因为set堆放的是一堆不重复值的集合。所以可以做全局去重的功能。为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个做一个全局去重,再起一个公共服务,太麻烦了。另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
实现方式:set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。当一个集合只包含整数值元素, 并且这个集合的元素数量不多时, Redis 就会使用整数集合(INTSET)作为集合键的底层实现。
Sorted Set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。另外还可以用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
实现方式:Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。